If the owner or maintainer of a project does not want AI-generated code in their project, people should not submit AI-generated code to it. That people so often do does not mean the project should allow it: it means we have a culture that fails to understand consent.
Recently, Fedora adopted an “AI-assisted contributions policy“. The short version of it: AI coding assistance is allowed, if you disclose its use.
You MAY use AI assistance for contributing to Fedora, as long as you follow the principles described below.
Transparency: You MUST disclose the use of AI tools when the significant part of the contribution is taken from a tool without changes. You SHOULD disclose the other uses of AI tools, where it might be useful.
The Linux distribution Bazzite, for reasons unknown to me, decided to defend that policy on BlueSky with this reasoning (emphasis mine):
To add, without this change Fedora would be shipping AI-assisted code anyway. If Fedora had a no-AI policy people would just break it, meaning Fedora contributors wouldn’t know if specific code was assisted by AI or not.
So long as rules can easily be broken, they will be. This prevents that.
Xe, author of the anti-LLM-scraper tool Anubis (which itself was LLM-assisted) shared a post on Bluesky that takes the same stance, with a very similar argument (emphasis mine):
Something I’ve seen around the internet is that many projects want a blanket policy of no AI tools being allowed for contributors. As much as I agree with the sentiment of policies like this, I don’t think it’s entirely realistic because it’s trivial to lie about not using them when you actually do.
This argument is bullshit.
The crux of it is simple: People will lie about using generative AI. Rather than trying to enforce a no-AI rule, where people will then submit AI code as their own, make using it require a disclosure. Sounds great on paper: it’s industry self-regulation. Just ask people to follow the rules, and hope they follow along.
An obvious conflict of interest arises: “what if the people using AI still lie about using it?” If you’ve already established that people willing to use generative AI are willing to lie about it, then why would this stop them? If there’s nothing wrong with submitting AI-generated code, then why should they need to disclose it? Even if they get busted for not disclosing it, the penalty is nothing: it’s a trivial mistake, a simple “git commit –amend” away from being acceptable.
Allowing it with a disclaimer makes it easier to slip in non-disclaimed, AI generated code, too. Assume the logic works, and people are submitting their AI-assisted slop with proper “Assisted-by” annotations. That gives rise to the assumption that someone who doesn’t use that annotation it didn’t use generative AI: the whole reason to allow it was because otherwise people would lie about its use!
It is strange to me to consider bad actors only in the case where it favors your argument.
The original post continues:
Anyways, at a high level if you ask people to disclose what AI tools they are using and make it so that the default configuration of most AI tooling will just add that disclosure for you, people are much more likely to comply with that policy. I think that this is a better middle ground than having witch hunts trying to figure out who used what tool and letting it become a free ground for noisy, low‑quality contributions.
The language choice of “witch hunts” is also interesting, especially when your entire argument revolves around people habitually lying. Is it still a witch hunt when there’s actual witches? The author specifically points out their LLM coauthor wanted to use a different phrase, too:
For what it’s worth, I had to fight the local AI model over the use of the phrase “witch hunts”. It really wanted “targeted investigations” instead.
Hmm.
Finally:
I want to see a future where people are allowed to experiment with fancy new tools. However, given the risks involved with low‑effort contributions causing issues, I think it’s better for everyone to simply require an easy machine‑readable footer.
I feel like I have to point this out: You can already do this. You can already run an LLM and have it generate a whole project for you. Nobody is stopping you from doing that. You can also download a project, and make your own additions to it. Again, nobody stops you. Go nuts.
People can say, however, that those contributions aren’t welcome in their project. If someone copies a GameFAQs entry for TCRF, it’s removed for being plagiarism. Do people lie about sourcing? Absolutely. Does that mean we allow it? Absolutely not! It just makes those people liars, and when we find out they’re liars, we deal with them.
Ultimately
This argument treats rules and consent as optional. Something you can and should ignore if you think it’s too difficult to follow or obtain.
If the owner or maintainer of a project does not want AI-generated code in their project, people should not submit AI-generated code to it. That people so often do does not mean the project should allow it: it means we have a culture that fails to understand consent.
No means no.
This post was written over the course of a few hours, without the assistance of any generative AI or LLM tools. I can take pride knowing that this work, mistakes and all, is mine. It is my skill, my voice, my writing.
I want to note that my post does not consider things like “ethical data sourcing for training”, “external costs of training the models”, “costs of compute to run them”, etc… It is simply: if a maintainer says do not use a tool in their project, that means do not use the tool in their project.
Or, in short, “it’s 2025, man, you really don’t gotta allow Pokemon: Racism Version.“
Update 2 (10-08-2025): RetroAchievements has posted an official announcement with new policies and clarifications around what is and isn't allowed, and it addresses the points I wanted below. My only remaining complaint is that we shouldn't have gotten here in the first place, and they fumbled the initial response really badly.
Update: Since posting this I've gotten several comments via tor full of slurs, and one random person in the official RA Discord attempting to doxx me, if you're wondering how that's going.
The RetroAchievements platform posted an update todayacross the front page of the website that, among other things, made some curious announcements:
Recent discussions in our community have raised important questions about the scope of our Code of Conduct and our approach to game content. We want to address these questions publicly so the entire community has clarity on our policies and practices.
On the scope of our Code of Conduct Our Code of Conduct governs user behavior within RetroAchievements community spaces: how members interact with each other in comments, forums, and Discord.
It does not govern the content of games or ROM hacks for which we provide achievement sets.
RetroAchievements functions as an archival platform. We provide achievement sets for games and ROM hacks as they exist, without curating based on their themes, content, or messages. This includes commercial games, from various eras and regions, homebrew projects, and community-created ROM hacks. The presence of an achievement set on our platform does not constitute endorsement for a game’s content, nor does it reflect the personal views of our volunteer developers, moderators, engineers, or administration.
…
Our position on archival vs. curation We recognize the tension between archival preservation and community safety. Different platforms resolve this tension differently. Some curate heavily based on content, while others preserve more broadly.
RetroAchievements has chosen a preservation-focused approach, prioritizing archival completeness over content curation. This means we host achievement sets for games and hacks that contain content some community members find deeply offensive.
First of all, as someone involved in archival and preservation, it is extremely strange to me to consider this “preservation” or “archival”. What it is, is creating a all-new set of achievements and conditions for old games, and rewarding the people who engage and play with those additions. There’s nothing wrong with this, but it’s not archival or preservation. It’s a stamp card.
In most cases, it isn’t the developer or programmer of a game adding RetroAchievements; it’s a third party reverse-engineer, finding what variables in memory are associated with progress in game.
One thing to note, too, is that the community already has “User Code of Conduct“, includes these examples of “unacceptable social behavior”:
Bigotry: This includes racism, sexism, elitism; intolerance regarding others’ nationality, religion, sexual orientation, political beliefs, etc.
Public or private harassment.
Defamation, as in making false statements about a person that may injure their reputation.
Threats of violence.
Unwelcome sexual attention or advances towards others.
Posting pornography, as in images or descriptions of erotic behavior intended to cause sexual excitement.
Posting gruesome or gory images intended to cause disgust.
These are all pretty reasonable rules for keeping a community safe and trusting. There’s nothing wrong with them at all, in fact. The critical part is that these are only for the users. Not the content.
Enter: Pokémon Clover
RetroAchievements accepts sets for ROM hacks, which are mods for existing games. These can be as simple as a new set of levels (or graphics), or as elaborate as entirely new gameplay concepts or genres.
Pokémon Clover, named after the 4chan logo, had a RA set in development for years… and it was finally due to release. What is Pokémon Clover? I’ll let the site itself explain:
The main point of Clover is to be both a parody of 4chan’s imageboard culture as well as a parody of Pokémon as a whole. It thus contains themes and language not suited for the faint of heart.
Emphasis mine; it is, essentially, a shock hack. It’s designed to offend as many people as humanly possible. A gym leader who gives you the “Aryan” badge; monsters named “Furnazi” and “Kuklux“, among countless others. It’s not exactly subtle.
Which makes it all the more bewildering that RetroAchievements would choose to allow it! Needless to say, the front-page combination of “new guidelines” and “new game supported by these guidelines” caused quite a stir.
You know, exactly as it was designed to do. Kind of the whole point of a shock hack.
Pokęmon Clover is not an example of ancient ROM hack crust, either: it’s a recent project, with its last update two years ago.
As one would expect in this environment, many users revolted! The announcement thread drew 42 pages of replies, spanning from “why are you doing this” to cheering for not “censoring” things.
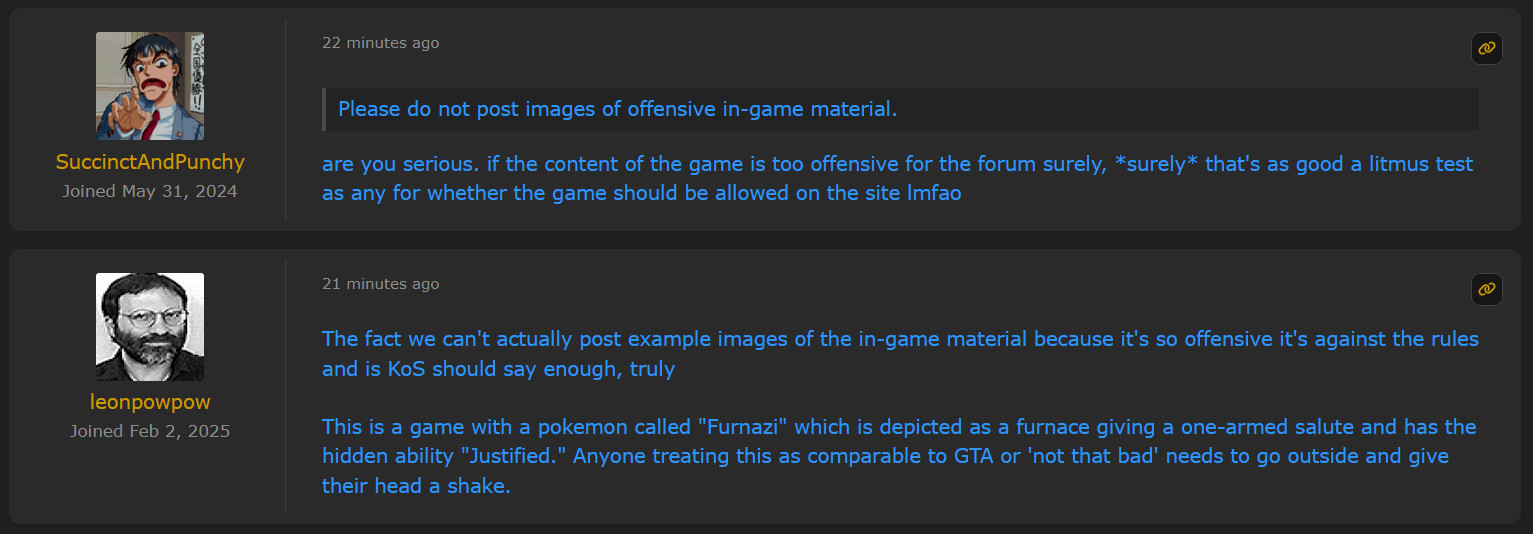
MOD: Please do not post images of offensive in-game material. USER 1: are you serious. if the content of the game is too offensive for the forum surely, surely that’s as good a litmus test as any for whether the game should be allowed on the site lmfao
USER 2: The fact we can’t actually post example images of the in-game material because it’s so offensive it’s against the rules and is KoS should say enough, trulyoh, so the content DOES matter and the news post was full of shit? Mod: The Code of Conduct applies to our community, not the games. We do not allow such content in the achievement titles, descriptions, or badges either.
This makes it explicit: the game openly and flagrantly violates the User Code of Conduct. Buuuuuuuuuut, because it’s not hosted here, it’s fine to have a set for it on the site.
You just can’t actually, um, discuss it, here. At all.
At this point, in their shoes, I would immediately close the forum thread, post a “holy shit oops we made a big fucky wucky”, and throw the set into the garbage. Then I would reopen the thread, post “any off-topic shit gets you banned for a week”, and enforce that strongly. The thread has been full of nonsense slippery slope arguments (“if we ban this one game, where will it end!?“) and wild hyperbole (“they’re calling for murdering mods!” was someone’s misrepresentation of one poster saying the mods should “go”). Exciting stuff!
A few hours and 42 pages into the mess, the founder steps in and closes the thread:
I’ve locked this thread for the moment as we don’t need any further discussion about the Pokemon rom-hack. This news article was to address an uncertainty in the user Code of Conduct, which has been done. We are considering the feedback that you have provided and we will follow up with an announcement shortly.
Great! Progress! The important thing is to get that decision out soon, stand firm with it, and keep things focused so that bad-faith bullshit doesn’t come stir up trouble. Again: It’s 2025! There’s no place for this garbage and you know it.
Alas.
Posting Through It
I don’t want to hammer too hard on it here, but: if you say you’re locking discussion and coming back with an announcement, lock the discussion and come back with an announcement. Instead, in a second thread:
I asked for 177 to be taken down because I don’t want RA to appear to in support of a game that solely exists to help the player simulate rape and reward them for it. That was my personal decision and I stand by it. I don’t wish to ban or remove any legal or legitimate content on RA, I’ve never done so in 13 years, but I don’t feel comfortable keeping that particular game on the site.
“177” (described as “A bishoujo game revolving around rape” which “ignited a public furor […]“) is another one of those “kind of obvious not to include this” entries, but in posting this, there’s now a clear line you can cross that isn’t “illegal” or “illegitimate”.
And from that, everything that thus isn’t, is now a personal endorsement. Certainly so once you’re aware of what it is that you’re choosing not to remove.
Today, we have made an announcement regarding a policy clarification on our User Code of Conduct. This was met with serious concerns, and we fully acknowledge that we have let the community down by how we handled it.
First of, we would like to apologize for how this started in the first place. We posted this announcement in the forum post of Pokémon Clover, which (understandably) associated the announcement specifically with that game. This policy clarification was meant to be regarding transparency of our policy in general, and was not meant to be associated with a single game. Pushing this to the front page did not help, and for that, we do deeply apologize.
One concern that was brought up was regarding our stance as an archival platform not curating what games we allow on our platforms, aside from games that have been deemed illegal. This obviously raised concerns that, given our stance, we are also in favour of allowing an edgy Pokémon hack that glorifies hate speech. This obviously goes against our ideal of a retro gaming platform, and we have no intention to ever be associated with hate speech.
Effective immediately, development on Pokémon Clover is stopped and it will not be released on RetroAchievements.
Internally, we are going to discuss how to move forward with content like this in the future. This will take time, because we want to be absolutely sure we reach a conclusion that we can truly stand behind. We have lost goodwill today, but we will do our best to ensure we live up to the expectations you have for us.
There’s that word again, “archival platform”. I do not think that means what you think it means.
But this is largely a non-commitment. The hack in question is banished, but it is, again, a single line item. There’s a promise of future action, but nothing in the present.
Further smoldering
A lack of direct and decisive action, including in stepping in and going “stop making bad-faith, slippery-slope, etc. arguments“, has left the Discord channels in slow-mode, with constant bait and shit-stirring arguments. Some people try to repeatedly suggest that “every” “offensive” game should be banned; others argue that it’s “just a joke” and people “shouldn’t be offended”. This argument has, flatly, dominated the general chat for the last few hours.
There have been talks of making a “blocked games” list, so you can hide recommendations about games you don’t want to play. The implication is that this would greenlight so-called offensive hacks, since, well, you can just hide the ones you don’t like. (Never mind the further implications behind this, like “showing people racist stuff before they know/can block it”, “people highlighting it on their profiles”, etc…)
Even as I am typing this, bickering continues, with the occasional image spam. People coming in and pretending “Has anyone played it? They keep saying it has hate speech, but…” (see above links for evidence it does), etc. Nobody is there to stop it that I can tell.
Nobody likes taking medicine
As I’ve said before, I have a simple solution to this problem: take a hard stance. Make people take their tolerance medicine.
No games or mods designed as, promoting, or containing shock content, racism, bigotry, or other content prohibited under our Code of Conduct
No games or mods that are illegal or illegitimate
This is a bit of a simplification, and also makes it subjective. Example: Conker’s Bad Fur Day; that’s a commercial game that was “offensive”, but came out, had ratings, and wasn’t focused on being racist (mostly just offensive and crude). It got appropriate ratings. Clover, being primarily made as a shock hack, doesn’t qualify; it’s designed as a vehicle for racist jokes.
This change would piss people off, 100%. Any change does. But it says to minorities and others: we don’t tolerate this kind of behavior here, not even as a Trojan horse in the form of an RA set. The people who leave over this aren’t the kind of people you want around; there’s a reason the term “Nazi bar” has been getting thrown around.
Hoo okay this just scrolled by and it’s a whopper
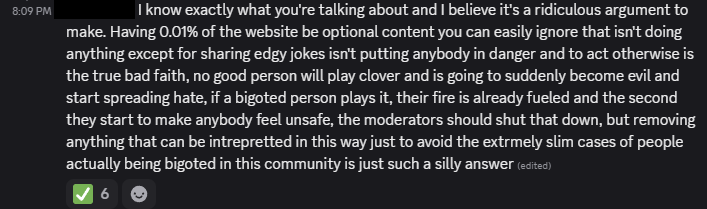
The problem is this is one of the most well-regarded Pokemon hacks despite the offensive parts, and one of the most requested games on RA. In order to dismiss that, people have to attack the character of hundreds of people they don’t know, or just say “I’m in danger” or “they want to kill me” and attempt emotional blackmail. In my opinion it would be a good compromise to hide the game from view on the site while still allowing people to play it if they wish
I love the wording here. “Asbestos is a great insulator, despite the cancer.” Note also the strawmanning; nobody has been saying that. It’s a classic tactic that has been going on in this Discord for hours, and it will likely continue for hours more. Speaking of,
It’s just edgy jokes, and to act otherwise is the real bad faith *fartz*
At some point you just have to say, “enough.” Remember: The thing sparking this debate was a shock hack full of blatantly racist, pro-Nazi images. It is still being brought up as something that should be allowed on the site! Right now! The conversation has not been put to rest.
To say I’m disappointed at this point would be an understatement. Many streamers I follow use and enjoy RetroAchievements in their streams; friends claim it’s gotten them back into classic games. In today’s world, being around as long as it has, I don’t know how we’re still having this debate. I just don’t.
I run a website called The Cutting Room Floor, a wiki about cut/unused content in games. The server has been getting hammered by a whole host of LLM scrapers, malicious bots, and other problems.
The first type, LLM scrapers, are fairly well known at this point. They operate by simply scraping every single page of your website, as fast as possible, in the worst way possible, ignoring flags like “noindex” and “nofollow”. The naïve part comes into play because many sites, especially dynamically generated pages like wikis and code repositories, have very deep links to all sorts of historical views of pages — old versions, comparisons between arbitrary old versions, statistics and info pages… A scraper bot will just grab all of those without care of their value (or cost).
The LLM scrapers largely come from cloud providers, especially low-quality ones that are rife with abuse. If you block their scraping attempts, they will simply start up a new VM on their provider of choice, do more scrapes until they’re caught, repeat ad infinitum, until you give up and black hole the entirety of PureVoltage/OVH/DigitalOcean/Amazon/etc. The particularly sophisticated ones spread out their requests across multiple IP addresses in the first place, too, making identifying them much harder.
A subtype of this is the “wannabe archiver/preservationist”. You know the type: “This website is important. I should save it. I will do this by single-handedly downloading the entire website.” We’ve had these kinds of clowns, too. In a sense, it’s similar to a bank run, complete with largely just making the problem worse for everyone.
Those bots are bad, but at least they want the content of the pages, even if it is for no noble goal. Far more insidious are the straight-out DDoS bots.
The DDoS
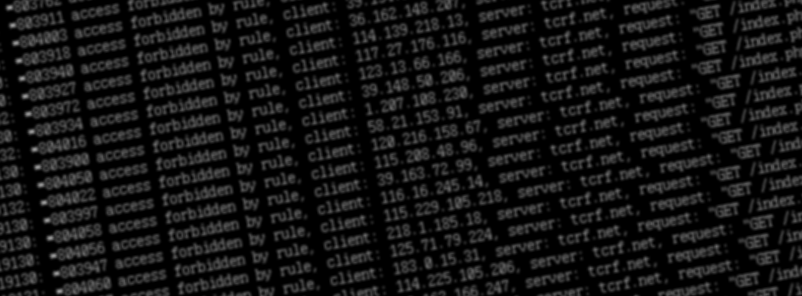
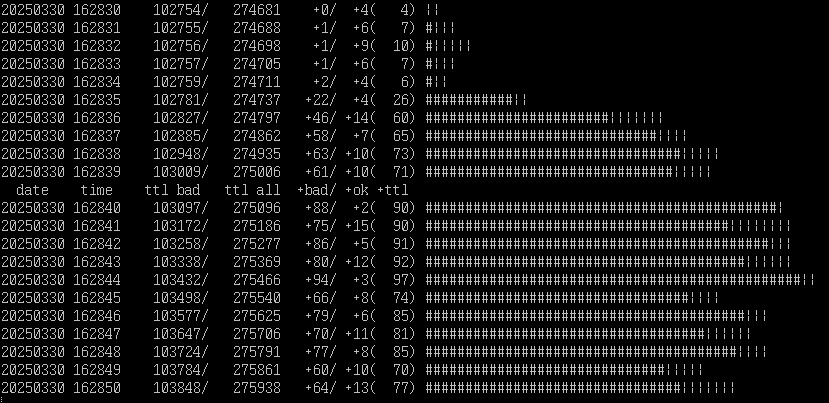
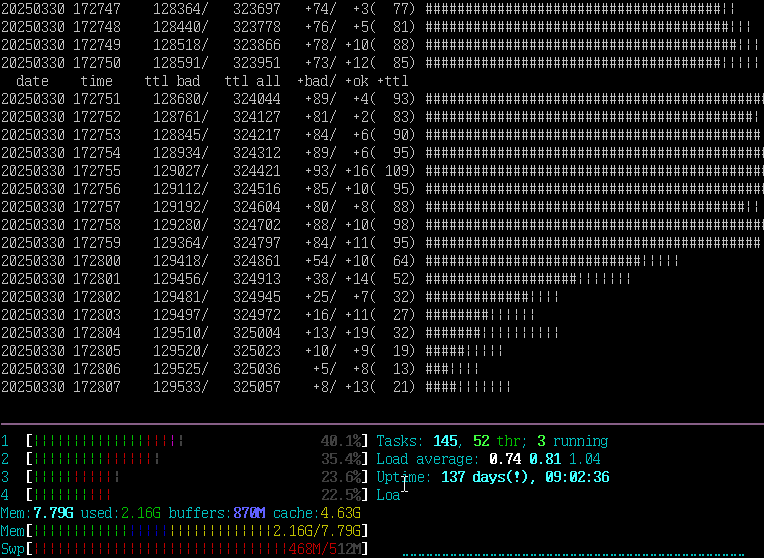
Here’s a bit of a graph from the TCRF server, one of the analysis tools I made and use. It simply shows a running count of “how many accesses were made to the web server this second”, split across blocked accesses (403s, indicated with a “#” on the bar) and all others (indicated with “|”). This is right as one of the DDoS waves came in, and you can see things jump from TCRF’s stable “5-15/sec” to nearly 100:
This particular DDoS has been ongoing since early January in various forms, and as far as I can tell seems to be targeted at us directly. Thousands of IP addresses, all making one or two requests, all at the same time.
These attacks typically last for a minute or two. The bots have certain pages and features that they disproportionately target: “expensive” pages to generate. For the first few months — before I’d actually pinpointed it as a DDoS — they mostly focused on making excessive calls to “Special:RecentChangesLinked“, a page that shows a page’s history and the history of every page linked to it. By simply requesting 5,000 different pages’ worth of interlinked history, the server grinds to a halt and nobody else can access a page.
When that attack was mitigated by making RecentChangesLinked login-only, The next attack has largely focused on just blasting random history / comparison pages, again with the strategy of “spend as much time executing worthless requests as possible so that nobody else can get in”. Note that almost all of these are within the same second, and from a wide variety of IP addresses, almost all Chinese-based:
It’s not as useful to attack a basic content page, because the wiki will simply give you the cached version. So the bots go after these deep, dynamic pages to waste resources.
Stopping the insanity
Stopping the attack on the site has been an ongoing process, employing multiple methods.
One tool that cropped up recently and got remarkably popular is Anubis, a service that sits in front of your webapp and presents connecting users with a challenge. The challenge effectively requires a client to waste several seconds/minutes doing expensive-to-do but easy-to-verify math, under the idea that bots won’t waste time doing it (if they are even using a client capable of handling it). Anubis seems great, but isn’t really workable for TCRF for a few reasons:
It requires Docker, which TCRF doesn’t use, and which I don’t want to have to learn, stand up, and add to an already-exhausting maintenance load
It requires you to use nginx as a reverse proxy to a “web app”; TCRF uses nginx as a web server, not a web app, so there is nowhere to slot it in without standing up even more services
It presents its challenge to everyone
If you’re setting up a modern web app, by all means, but the costs of implementing it here are too much.
Another suggestion that has cropped up is Cloudflare. Cloudflare likely needs no introduction: they’re a content-delivery-network that you place in front of your web server, and as part of their services they offer anti-DDoS protection. The problems with Cloudflare mostly stem from disagreeable politics, not wanting to rely on an external third party, and (again) having to set up something else in the middle that breaks all the workflows. And, again, I’m not the biggest fan of putting an interstitial in front of every single person.
So, what do you do?
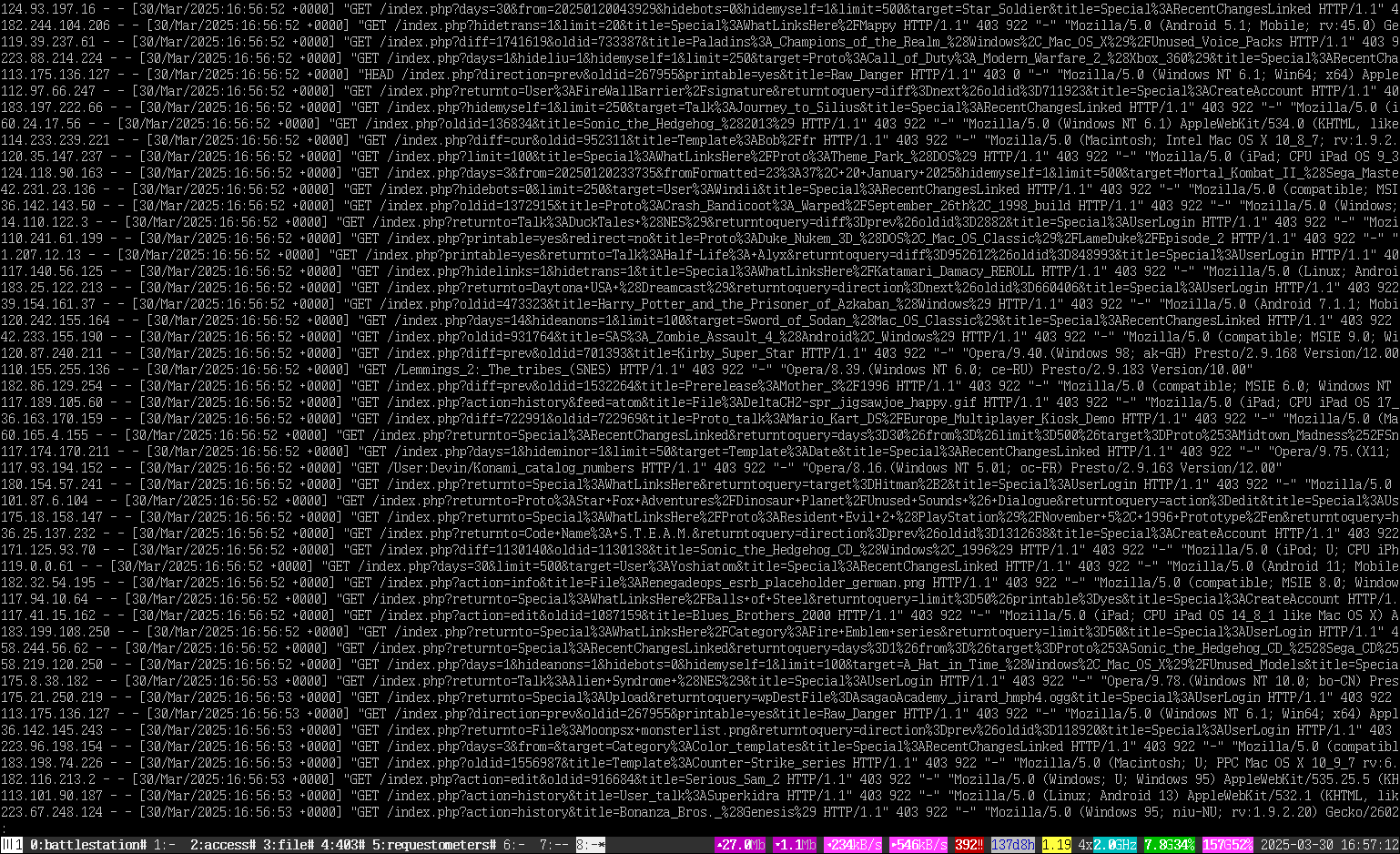
Before analyzing the logs and determining that a lot of the abuse was coming from one particular location (China), the first step was simply to limit access to the most expensive pages. Since this is a simple PHP site, I was able to do this by just inserting a bit of magic into the index page; you might be able to see it if you go directly to one of the blocked pages in an incognito tab. It’s not the best, but it’s short, simple, and (most importantly) prevents the server from wasting additional resources on the request. Logged in users never get this message.
Your request was blocked. Try disabling any VPNs or proxies and try again. If problems persist, please get in touch via Discord (https://discord.gg/wnfBf5D) or IRC (irc.badnik.zone #tcrf, slow)
Then: block. Block block block. So far, most of the problem has come from a handful of networks, or ASNs. They use many IPs within those networks, but they’re still from that network. So: Block ’em all!
As a live example, one of thousands of the malicious IPs was from “219.142.153.182”. A quick look at ipinfo gives us little reason to be surprised: it originates in China, a common theme for these bots. So, simply take the AS number, “AS4847”, throw it into asn.ipinfo.app, and presto, a blocklist ready to drop into nginx. Do this about 20 times, and the DDoS starts to run out of networks it can abuse you from.
The full list of network blocks on TCRF is long and only getting longer, but it includes a frustrating number of Chinese-based telecoms, mobile networks, and cloud providers, especially Alibaba. Holy shit Alibaba is one of the most abusive networks I have ever seen, and I’m not lying when I say any sysadmin’s first step should be routing it to a black hole.
The advantages of all this is that, for most users, it’s completely transparent. Anyone can still use any old browser (even on Windows 98), there’s no intrusive waiting pages or CPU-melting Javascript challenges. The downsides are that innocent users can (and will) get caught up in these blocks, and since not everyone is subjected to the methods, there are ways to bypass it.
But at the end of the day, it’s extremely effective, and even with 100 requests/second, the requests being blocked means it doesn’t even cause a blip on the server.
And yes, there were DDoS waves hitting the server even as I was writing about it. For now, the attacks are impotent.
Here’s a Bluesky post with a video of what the access log looks like when it happens (about 15 seconds in):
i wanted to record a video of what it *normally* looks like, but of course this bozo had to fuckin interrupt it
I mentioned in the previous post about my DIY network monitoring that I’d put the code up eventually, and that time is (or was) now. It’s still not really cleaned up, but if you want to run it, you can do that now.
It requires fping, which is a tool you should be able to install from your package manager. It’s basically ping but with slightly better output for script use.
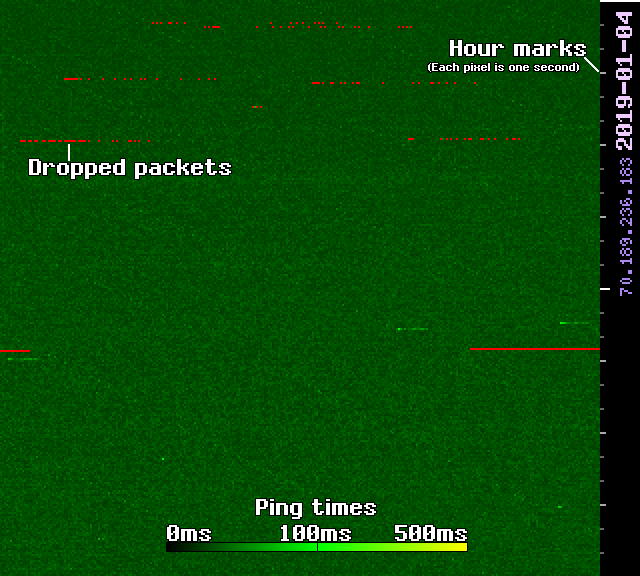
I’ve been posting images on Twitter and elsewhere lately that are largely green squares with red dots on them. While I intend to write a longer post on that later, for now, I’ll make a quick explanation of them.
These are quite good at showing weird network behavior and other anomalies, but not good for diagnosing why.
Each pixel represents a test done on one second; each row is 300 pixels, or 5 minutes. Seconds go from left to right, top to bottom, and hours are ticked off by marks along the right edge. Faster times are denoted with darker greens, getting lighter as they approach 100ms, and turning yellow as they reach 500ms. Packets that aren’t received within half a second are marked lost, and show up in red.
Ideally, I wouldn’t have had to make this tool, but we’ve had three different cable technicians inspect our equipment with no improvement, and we’ve also purchased a newer modem. While the new modem helped, it’s only because it’s able to achieve even more out-of-spec power levels, and not because the old one was faulty.
Unfortunately, we haven’t managed to correlate this to anything going on inside or outside our apartment, so all we can do is monitor what’s happening for now… and use it as further evidence that the problem still isn’t fixed.
We’ve been having a lot of internet issues at the Romhaus, the subject of which will have to be a topic for another post.
While we’ve been trying to get it fixed, one of the things that was recommended to us by Cox was purchasing a new modem to replace our old (but still otherwise functional) Arris Surfboard, as it supported only DOCSIS 3.0 and was a few years old. We decided to replace it with a shiny new Motorola MB8600, which was the only DOCSIS 3.1 modem we could find nearby. (Unsurprisingly, it didn’t help, so that was a cool $160 we spent on not fixing the problem.)
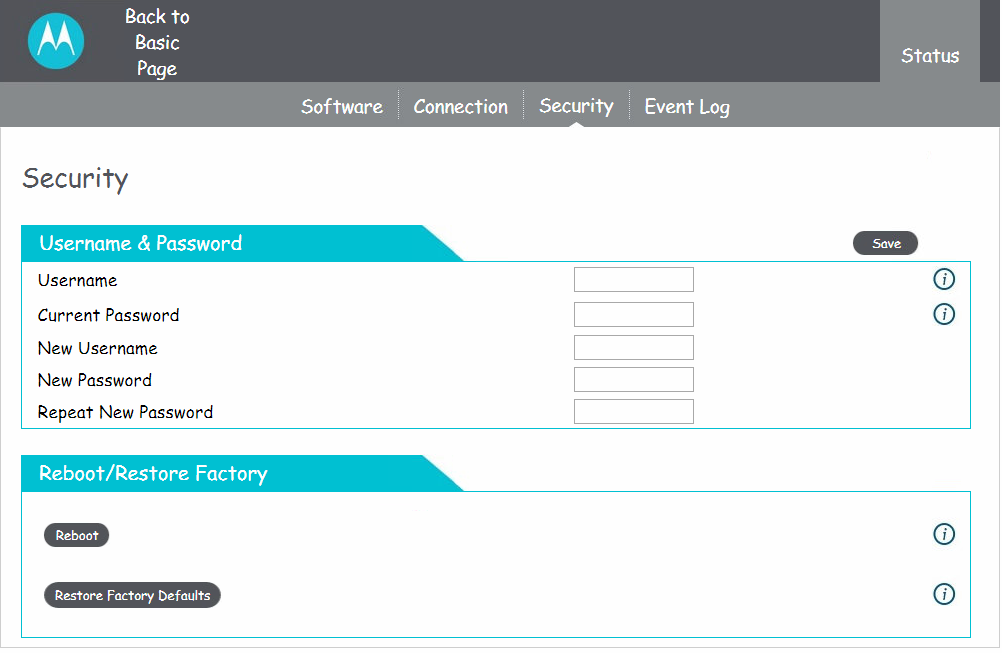
While the old modem had no authentication, it also didn’t pretend to. There also wasn’t anything you could actually do with it — it was strictly a view-only interface, as far as I remember. The Motorola instead requires a username and password to log in. Logging in allows you to reboot the modem, restore it to factory defaults, or change the username and password.
why
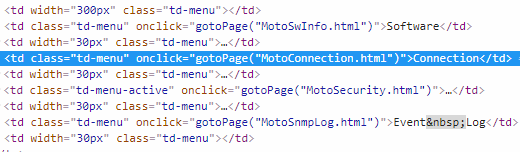
The entire interface is a mess of Javascript in place of meaningful HTML; rather than using normal links, everything is based on onclick events. The layout is built on tables within tables within tables, even in places where it isn’t useful (for example, the header of each table is itself a table, with the green-to-white transition provided by an image). There’s no reason for any of this, and it’s usually a sign of bad design further down.
And of course it is. As part of my network monitoring, I wrote a script that checks the connection status page and extracts the power levels, to help diagnose our ongoing issues. With the old modem, it was just a matter of requesting the status page; with the new one, that’s behind a login page, so I had to figure out how to have the script log itself in.
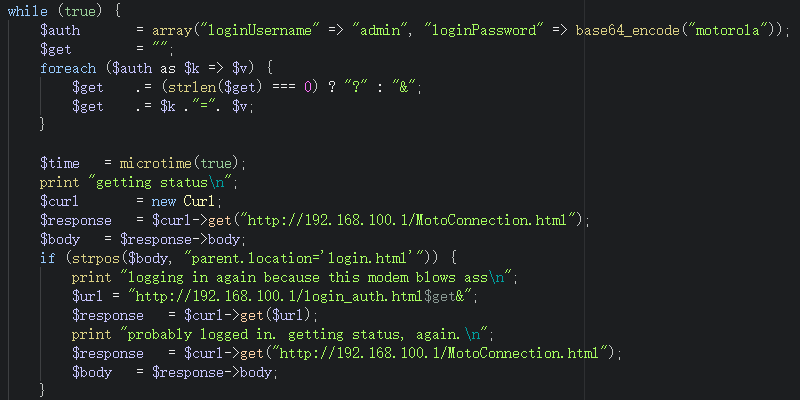
Beyond the login form being a further mess of needless JavaScript (you don’t need onBlur and onFocus if you just use ::placeholder like normal people), I dug through the login page to figure out how, exactly, it logged you in. And of course. Of course it’s horrible.
function btnApply() // (Called when you hit submit)
{
var loc = '/login_auth.html?';
with ( document.forms[0] ) {
loc += 'loginUsername=' + encodeUrl(loginUsername.value);
loc += '&loginPassword=' + encode(loginPassword.value);
loc += '&';
var code = 'location="' + loc + '"';
eval(code);
}
}
aaagh
What this does, in human terms:
URL encodes your username.
base64-encodes your password.
Glues those together into a URL, “/login_auth.html?loginUsername=(url-encoded username)&loginPassword=(base64-encoded password)&“
Prepends a JavaScript fragment to redirect you to that URL and executes it.
Yeeeep, it sends it over GET, completely in the clear. Making the script log in after finding this out was trivial.
And somehow this isn’t even the worst part
That’s bad enough, but there’s more. Because of course there is.
When I first started developing this, I didn’t need to log in at all. It turns out that — surprise! — logging into the modem authenticates it for everyone. If you log into it on Computer A, and then open the modem page on Computer B, you’ll be presented with the information screen, without needing to log in again. At first I thought it might be a fluke or based on IP addresses, since I had the page open in my browser as well, but after letting the script log in, I opened the modem page on a computer in another room that hadn’t been touched for hours and, well, I didn’t have to log in.
So you don’t even need to sniff the password; you just need someone to log in for you.
I hate computers.
UPDATE!!! As pointed out in the comments, the current usernames and passwords are straight up dumped in plain text in the Security tab. I can’t even make this shit up, oh my god.
Jul‘s a forum I run. If you’ve been around me for a while, you’ve probably heard of it. It’s a fork of an ancient forum, both in the sense of community (from Acmlm’s Board) and software (Acmlmboard). They were created by (surprise) Acmlm back in early 2001, 18 years ago. The community went through a lot of… turbulence over the years, branching into several different, smaller communities, before mostly settling down around 2010.
While a full genealogy chart is a little much for the first post about it, especially at 11:40 PM, there are a lot of variants and forks of the code, as well as several attempts to recreate it. Jul runs on a version that’s more similar to the original than most modern ones, though.
As most of the internet has moved on to social media like Twitter and Facebook, forums have been left behind. They’re simpler, they’re not centralized, and they’re a lot more relaxed. Forums aren’t going to send you push notifications or flood your e-mails or shove a bunch of recommendations in your face, and for that they fall behind the “engagement” metric… but as a long-form place to organize, discuss, and just hang out? Can’t beat them.
The code Jul uses is on GitHub, though it’s still full of Jul-specific hacks features and isn’t really usable on its own. It has no installer or readme, no guides, and is, frankly, a mess. Even then, it still manages to run, over 18 years after it was first made! Pretty impressive.
One of Jul’s more notable features — shared with other Acmlmboard-likes — is the ability to make “post layouts”. Unlike typical forum signatures, post layouts (and posts themselves) can include full HTML, both before and after a post, letting you flair your posts with a touch of style. Of course, users can also disable those by default if they’re too obnoxious.
Anyway, this post was brought on because I did some updates to it, mainly in redesigning the new reply page:
The new reply page now simply shows an error if you’re logged out and give an invalid username or password, instead of cancelling your post entirely. Of course, if you post while logged in, you never see this.
The changes are fairly minor, but hopefully make it nicer to use:
“Mood avatars” are a dropdown instead of a large list of radio buttons
Posting while logged out and putting in an invalid username/password will return you to the form, without losing your post
Internally, the code is cleaner and better organized
The post reply box can now be resized fully, instead of being locked to 800px wide
Post previews now use the same form as the initial reply, instead of a separate one (for some reason)
In the event that you aren’t able to post your reply (because e.g. the thread was closed or moved to a restricted forum), you’re given a chance to copy what you had written — you no longer instantly lose it
The days of typing a long monologue only to lose it are (hopefully) over.
One of the goofier projects I’ve started recently has been toying with an Adaptive Micro Systems LED sign, specifically the PPD220RED (for “personal proximity display”, and its color). I’ve wanted to own a goofy LED marquee sign for years, and after some searching I managed to snag one on eBay.
Among other things, I’ve hooked it up to a Raspberry Pi and have it showing simple weather information, sourced from OpenWeatherMap.
The sign displaying the current weather conditions and a brief forecast.
The protocol for the sign is available online, and I’ve been working on an implementation of it so I can let the internet display messages on it as well. But for now it’s mostly just a silly little toy.
New year, new… thing? I’ve talked way too much about how social media sucks and yet it’s where I put way too much of my thoughts… and my journal isn’t really a good place for that, either, being that it’s more personal.
I’ve tried various blogs before — too many times, arguably — but this time hopefully I can keep things going by focusing mostly on what I’m doing, and have something to show for it beyond a link to a tweet or two.